Maixcam使用
注意:
- 模型转换时,分辨率需保持一致,若为640X640训练的模型,则后面onnx模型转换为. cvimodel模型时需要保持参数一致!!!(适用于Maixcam的分辨率参数是320X224)
- 遇到如下问题,先升级ONNXRuntime—pip install –upgrade onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple

一般升级后错误消失
- 在文件夹里放置的图片要求:
1.是数据集集里面的
2.大小必须一致
3.边长一定是32的倍数。如果不是32的倍数,就一定不符合模型的输入张量。补救的方法是用python脚本给他填充成32的倍数也行
用于yolo11n-obb模型:
OBB是什么?——和普通的识别框相比,OBB的识别框可以随物体的姿态转动,更好地标识出物体!你运行Maixvision自带案例中的ai_vision/nn_yolo11n_obb.py试试,看看这框真帅吧!而下图是我自己训练的模型效果:

有人会问:只看Maixpy官方文档的那个YOLO11-obb部署与识别教程可以吗?——可以,但是大概率会踩不少坑。你也许会遇到识别框无法旋转、INT8模型无法转换成功、运行模型后相机卡死、导入模型失败……等一系列烦人的事。所以,请将官方文档和我这篇文章结合起来食用效果更佳。
所用开发环境是Linux ubuntu22.04。若你是在Windows也没关系,其核心思想万变不离其宗。
如有更好的提议请告诉我,谢谢!
查看相机Maixpy版本
在相机内打开设置——设备信息,查看你的MaixPy版本。MaixPy不仅有电脑pip安装的,相机内部也有自己的MaixPy。要确保MaixPy是比较新的版本。
在Maixpy的github仓库中可以看到,自4.9.3开始才支持YOLO11-OBB检测(没找到YOLOV8-OBB是什么时候,所以最好用YOLO11来进行OBB检测)。如果你需要升级相机的maixpy版本,就要准备一个读卡器,烧录教程看maixcam官方文档的即可,很详细我这里就不说了。
采集数据集
大多数人常用相机里那个Maixhub客户端来在线设备采集,然而这种设备采集的曝光时间、增益值是自动的,如果你对数据集曝光要求比较严格,那就需要自己写个拍摄的程序。
例如我编写的是下面的采集程序。启动程序后,每秒拍摄4张图片储存在相机SD卡中。你可以随意修改它的曝光,设为-1代表自动。
from maix import camera, display, app, time
import os
# 设置摄像头分辨率
cam = camera.Camera(660, 280)
disp = display.Display()
cam.skip_frames(200)# 延时,等待相机稳定
exposure=cam.exposure(value = 3000)
gain=cam.gain(value = 3300)
# 保存文件夹路径。这是关于相机内的路径,和电脑路径无关
save_folder = "/root/photo"
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 设置拍摄频率(每秒4张)
capture_interval = 0.25# 每张图片间隔时间
last_capture_time = time.time()
while not app.need_exit():
img = cam.read()
disp.show(img)# 显示图片
current_time = time.time()
if current_time - last_capture_time >= capture_interval:
# 生成文件名
timestamp = int(current_time * 1000)# 使用时间戳作为文件名
file_path = os.path.join(save_folder, f"{timestamp}.jpg")
# 保存图片
img.save(file_path)
print(f"Saved: {file_path}")
# 更新上次拍摄时间
last_capture_time = current_time
time.sleep(0.01)# 稍微延迟一下,避免占用过多CPU下载、配置yolo11训练工程
给它单独开一个conda环境,我用的python 3.10。
从https://github.com/ultralytics/ultralytics下载源码,不用选版本,直接下就行。下载好后执行 pip install -r ultralytics transformers -i https://pypi.tuna.tsinghua.edu.cn/simple。之后如果报错缺少XX包,你就pip安装什么包。另外注意pip包之间容易有版本冲突,所以不能无脑下载,而是应该提前去百度包和包、包和环境之间的版本对应关系。
准备数据集
(1)数据集文件介绍
制作好的数据集的文件夹分布是这样的:
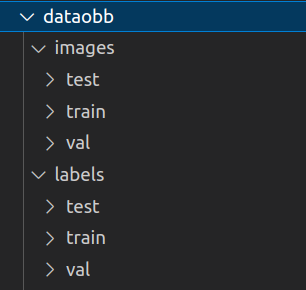
images/train 里面放训练图片,labels/train 里面放训练txt。
images/val 里面放验证图片,labels/val 里面放验证txt。
test里面可以是空的。
(2)txt格式介绍
用上海交通大学交龙战队开源的那个就行https://github.com/xinyang-go/LabelRoboMaster,它生成的txt格式完全符合标准。标注的方法看它的readme。
关于训练图片,最好是每张图片分辨率完全一样!!虽说理论上任何大小的图片都可以用于训练。但是训练的图片最好不要有的图片width过大、有的图片hight过大,因为之后训练的时候程序会给它们填充灰边使其统一大小。
(3)整理好的数据集放在哪都行,我习惯放在Ultralytics工程目录下。
获取yolo11n-obb.pt文件
从这个链接可以下载所有的官方pt权重文件https://github.com/ultralytics/assets/releases。注意我们要的不是普通的yolo11n.pt,而是yolo11n-obb.pt !!它俩结构不一样,只有后者用于检测旋转矩形。
使用yolo11s-obb乃至其他字母的行吗?——我的建议是一定要基于yolo11n-obb进行训练。我曾经试过 s 的,但是一开始推理相机就卡死、掉线,必须重启,说明相机内存爆了!去官网查看pt文件的大小,n 文件大小为5MB,而 s 文件19MB体量太大,其他字母的更不用说了,一个比一个大根本不能用。
必备的两个yaml(1)——路径与标签
在工程目录下创建myfile-obb.yaml,输入:
path: /home/wp/ultralytics-main/my_data# dataset root dirtrain: images/train
val: images/val
#test: images/testnames:
0: apple简单解释一下:train和val是相对于path路径的。有个一劳永逸、安全但麻烦的方法是都使用绝对路径,当然我上面的代码可没有这样做。
这里我只写了一个类别。你可以随意更改类别的数目、内容。
必备的两个yaml(2)——网络定义
先声明一点:这个yaml是官方的,自己不用写,我们常说的“基于yolo…”就是选择的这个yaml。
在 ultralytics/cfg/models 下,你会看到从v3到v11所有版本的yaml,里面还细分了pose、obb、普通等各种模型,这个 yolo11-obb.yaml 就是我们想要的,复制一份放在工程目录下。
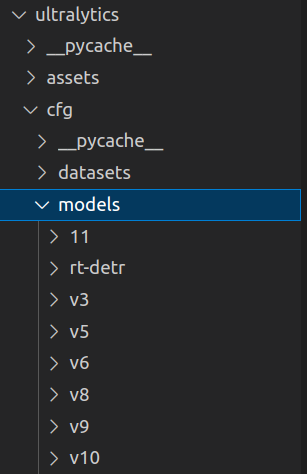
一定要重命名为yolo11n-obb.yaml,刚拿出来是不带s、n……这些字母的。
内容只需要改标签类别(nc)这个数字。
网上有博主给你的,其网络结构大概率和官方的这个yaml内容一模一样,用vscode对比就能看出来。
编写训练器train.py
在工程目录下新建一个train.py,那个imgsz是缩放 / 填充预处理,如果你的图片小于这个数,就会填充黑边再训练。其余的改改路径就行:
而v8训练出来的模型识别框根本无法旋转,角度永远输出-1.0000。
可能出现的问题:明明我指定的是yolo11s的pt文件,但是训练前期非要给我下载yolo11n.pt
先说明一点——不要使用yolo11s训练。不过我们还是要解决这个问题:找到amp这个参数,将它关闭就行。在ultralytics-main官方文件中,amp参数在ultralytics/cfgdefault.yaml 中,以键值对的方式,默认为True,把它改为False就行了。
from ultralytics import YOLO
def main():
model = YOLO('yolo11n-obb.yaml').load('/home/wp/ultralytics-main/yolo11n-obb.pt')# build from YAML and transfer weights
model.train(data='myfile-obb.yaml', epochs=100, imgsz=416, batch=4, workers=4)
if __name__ == '__main__':
main()检查训练结果,获得pt模型文件
训练好之后,在 runs/obb 下就能看到检测结果了。
pt转ONNX
工程目录下新建transform.py,代码如下。
这里的 width、height 一定要设置成32的倍数。如>果你没有设置为32的倍数,程序会悄悄设置成32的倍数,之后可能不符合你的预期而浪费时间。
转换成功后,在pt文件的同目录下就生成了。
from ultralytics import YOLO
net_name = "/home/wp/ultralytics-main/runs/obb/train5/weights/best.pt"
input_width = 864# 一定是32的倍数
input_height = 288
model = YOLO(net_name)
path = model.export(format="onnx", imgsz=[input_height, input_width], dynamic=False, simplify=True, opset=17)# export the model to ONNX formatprint(path)ONNX转mud和cvimodel
(1)确定ONNX模型的输出节点
上https://netron.app/查看ONNX文件的结构图。按ctrl+F分别搜索:/model.23/dfl/conv/Conv_output_0,/model.23/Sigmoid_1_output_0,/model.23/Sigmoid_output_0。看看有没有这三个节点,如果缺少了说明模型错了。
(2)部署并配置算能的tpu-mlir
- 先装好docker吧,用小鱼ROS命令装很轻松。终端输入:按照小鱼的指引一步步来就行。(Windows用其他方式安装)
wget http://fishros.com/install -O fishros && . fishros- 终端执行命令 wget https://sophon-file.sophon.cn/sophon-prod-s3/drive/24/06/14/12/sophgo-tpuc_dev-v3.2_191a433358ad.tar.gz 下载它的压缩包,下载好后执行docker load -i sophgo-tpuc_dev-v3.2_191a433358ad.tar.gz 。
- 在home目录下新建文件夹MaixCAM,在此文件夹下打开终端,执行 docker run –privileged –name MaixCAM -v $PWD:/workspace -it sophgo/tpuc_dev:v3.2 ,创建来一个MaixCAM的容器。没问题,然后关闭终端。
- 前往https://github.com/sophgo/tpu-mlir/releases,下载一个tpu_mlir-1.15b0-py3-none-any.whl,下载好后将它移动到MaixCAM,在文件夹内打开终端,输入 docker start MaixCAM && docker attach MaixCAM 打开容器,执行 pip install tpu_mlir-1.15b0-py3-none-any.whl ,完成后如下图所示。(3)将你需要转换的onnx文件放到MaixCAM文件夹中,再将一些待会测试的图片放进去。这里注意,test.jpg和images文件夹里的所有图片有3点要求:1.这些图片来自于数据集。2.大小必须一致。补救的方法是用python脚本用(114,114,114)的灰色填充为大小一致。3.边长一定是32的倍数。如果不是32的倍数,就一定不符合模型的输入张量。补救的方法是用python脚本用(114,114,114)的灰色填充为32的倍数。

这里的test.jpg的作用是什么?用于程序内部预处理验证、模型测试。从数据集中选取一张与模型输入相同大小的图片即可。images里面的图像作用又是什么?你会发现这只是专为INT8的转换而传入的。因为模型从浮点类型转为int类型需要生成“校准表”,用来调整网络中各种阈值参数。这个过程可以看做小规模的数据集训练,最后得到程序所需的参数。你需要从训练集中尽可能挑选各种特色鲜明、非极端情况的图片100~1000张。详细原理看https://doc.sophgo.com/sdk-docs/v23.03.01/docs_latest_release/docs/tpu-mlir/developer_manual/html/07_calibration.html
(4)建立转换脚本
新建 .sh 脚本,命名为convert_yolo11_to_cvimodel,里面输入下面的代码。
你需要修改的是:把net_name改成模型文件名字,宽和高改成模型输入口的大小。–output_names改成你自己的模型名称。
可能出现的问题:在容器内报错:[ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for Reshape(19) node with name ‘/model.22/Reshape’
那就在容器内执行 pip install –upgrade onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple 升级onnxruntime就行。
#!/bin/bash
set -e
net_name=my_obb
input_w=864
input_h=288
# mean: 0, 0, 0# std: 255, 255, 255# mean# 1/std# mean: 0, 0, 0# scale: 0.00392156862745098, 0.00392156862745098, 0.00392156862745098mkdir -p workspace
cd workspace
# convert to mlir
model_transform.py
--model_name ${net_name}
--model_def ../${net_name}.onnx
--input_shapes [[1,3,${input_h},${input_w}]]
--mean "0,0,0"
--scale "0.00392156862745098,0.00392156862745098,0.00392156862745098"
--keep_aspect_ratio
--pixel_format rgb
--channel_format nchw
--output_names "/model.23/dfl/conv/Conv_output_0,/model.23/Sigmoid_1_output_0,/model.23/Sigmoid_output_0"
--test_input ../test.jpg
--test_result ${net_name}_top_outputs.npz
--tolerance 0.99,0.99
--mlir ${net_name}.mlir
# export bf16 model# not use --quant_input, use float32 for easy coding
model_deploy.py
--mlir ${net_name}.mlir
--quantize BF16
--processor cv181x
--test_input ${net_name}_in_f32.npz
--test_reference ${net_name}_top_outputs.npz
--model ${net_name}_bf16.cvimodel
echo "calibrate for int8 model"
# export int8 model
run_calibration.py ${net_name}.mlir
--dataset ../images
--input_num 200
-o ${net_name}_cali_table
echo "convert to int8 model"
# export int8 model# add --quant_input, use int8 for faster processing in maix.nn.NN.forward_image
model_deploy.py
--mlir ${net_name}.mlir
--quantize INT8
--quant_input
--calibration_table ${net_name}_cali_table
--processor cv181x
--test_input ${net_name}_in_f32.npz
--test_reference ${net_name}_top_outputs.npz
--tolerance 0.9,0.6
--model ${net_name}_int8.cvimodel(5)生成cvimodel文件,制作mud文件
在容器中执行 chmod +x convert_yolo11_to_cvimodel.sh && ./convert_yolo11_to_cvimodel.sh 命令。如果没问题的话,在 workspace 就能生成cvimodel文件。
有2种精度,选一种拷贝一份出来(更推荐使用INT8,虽然精度低,但是非常快),改名为my_model.cvimodel,再新建my_mud.mud文件,内容如下,改一下模型名称,改一下标签。
[basic]
type = cvimodel
model = my_model.cvimodel
[extra]
model_type = yolo11
input_type = rgb
mean = 0, 0, 0
scale = 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
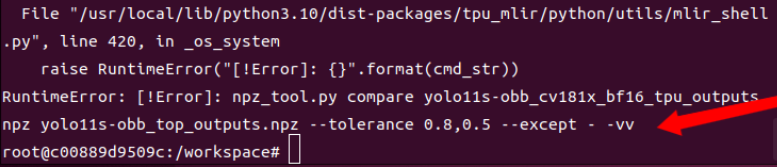
labels = apple很容易报如下图的错:这是因为文件夹中放置的用于INT8转换的图片不符合上述的3点要求,所以你再仔细检查检查。然而此时精度bf16的cvimodel文件已经输出了,你要是不用INT8,就可以不理会这个报错。
(6)模型导入MaixCAM,打包为软件
打开Maixvision,将相机连接。在文件管理器内,新建my_project文件夹,将cvimodel和mud文件同时导入。
在电脑上新建test.py输入下面的代码,Maixvision打开该文件然后运行。
from maix import camera, display, image, nn, app
detector = nn.YOLO11(model="/root/my_project/my_mud.mud", dual_buff = True)
cam = camera.Camera(detector.input_width(), detector.input_height(), detector.input_format())
disp = display.Display()
while not app.need_exit():
img = cam.read()
objs = detector.detect(img, conf_th = 0.7, iou_th = 0.65)# 阈值for obj in objs:
points = obj.get_obb_points()
msg = f'{detector.labels[obj.class_id]}: {obj.score:.2f}, {obj.angle * 180:.1f}'
img.draw_string(points[0], points[1] - 4, msg, color = image.COLOR_RED)
detector.draw_pose(img, points, 8 if detector.input_width() > 480 else 4, image.COLOR_RED, close=True)
# 打印识别框的信息print(obj)
disp.show(img)如果报错“’maix._maix.nn.Object’ object has no attribute ‘get_obb_points’”未找到get_obb_points这个函数,说明你相机内部的MaixPy版本低于4.9.3,一定要升级。